Consistent Hashing - System Design Interview Guide
Crack Your Interview With Our System Design Classes
Q. Can you explain consistent hashing?
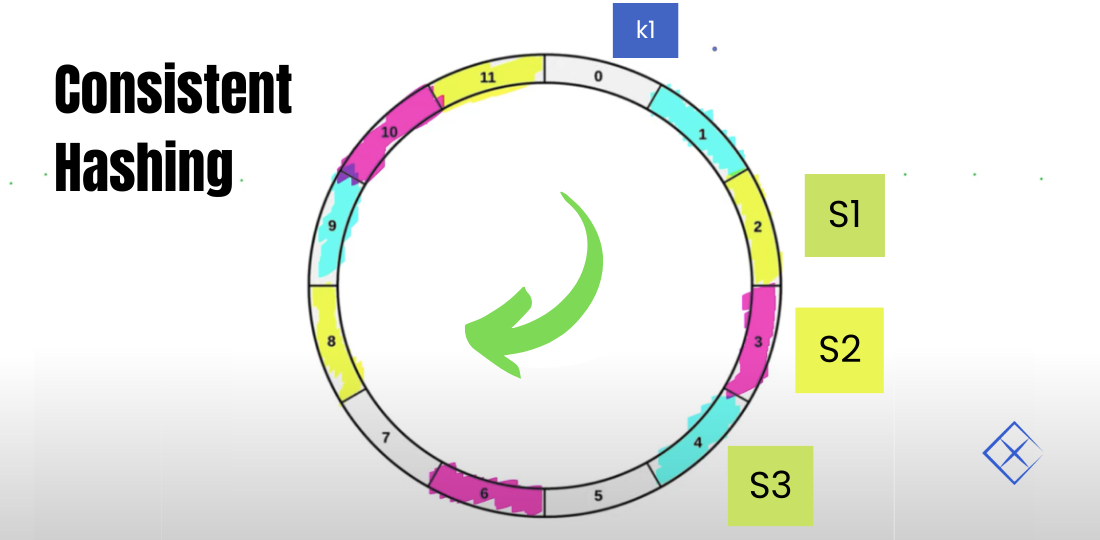
A. Consistent hashing is a distributed hash table algorithm that is used to distribute keys evenly across a cluster of servers. It is called “consistent” because the same key will always be mapped to the same server, unless that server is removed from the cluster. This is useful in cases where the keys are dynamic and the servers are constantly changing, as it allows the keys to be distributed evenly without having to completely rebuild the hash table every time a server is added or removed.
To implement consistent hashing, each server is assigned a range of hash values, and each key is hashed and placed on the server with the closest matching hash value range. For example, if there are three servers with hash value ranges 0-99, 100-199, and 200-299, and a key has a hash value of 150, it will be placed on the second server.
If a server is added or removed from the cluster, only a portion of the keys will need to be rehashed and moved to a different server. This is because the hash value ranges of the other servers will shift slightly to accommodate the new server, and only the keys that fall within the overlapping range will need to be moved. This allows the system to maintain a consistent distribution of keys even when servers are being added or removed.
Q. Can you explain the concept of virtual nodes in consistent hashing?
In consistent hashing, a virtual node is a logical representation of a physical server in the cluster. Instead of assigning a single hash value range to each physical server, multiple virtual nodes are used to represent a single physical server, each with its own unique hash value range.
The use of virtual nodes allows the system to distribute keys more evenly across the cluster, as it allows for a finer-grained control over the distribution of keys. Instead of having a small number of large hash value ranges, the virtual nodes allow for a larger number of smaller hash value ranges, which can more evenly distribute the keys across the cluster.
For example, if a physical server is represented by a single virtual node, and a key has a hash value that falls within the range of that virtual node, it will be placed on the physical server associated with that virtual node. If the physical server is represented by multiple virtual nodes, the key will be placed on the physical server associated with the virtual node with the closest matching hash value range.
Using virtual nodes in consistent hashing can improve the performance and scalability of the system, as it allows for a more even distribution of keys and reduces the impact of adding or removing servers from the cluster. It also allows for more efficient use of resources, as it allows the system to more effectively balance the load across the servers in the cluster.
Range-based hashing is a type of hashing algorithm that assigns keys to servers based on the range of hash values that the key falls within. In range-based hashing, the hash value of a key is used to determine which server the key should be placed on, based on the pre-defined range of hash values that each server is responsible for.
Range-based hashing is similar to consistent hashing in that both algorithms are used to distribute keys evenly across a cluster of servers. However, there are some key differences between the two algorithms.
One difference is that range-based hashing requires the server configuration to be fixed and does not allow for the addition or removal of servers without rebuilding the entire hash table. This can be inefficient and can lead to performance issues when the server configuration changes frequently.
In contrast, consistent hashing allows for the dynamic addition and removal of servers without the need to rebuild the entire hash table. This makes it more scalable and better suited for situations where the server configuration is likely to change over time.
Another difference is that range-based hashing does not use virtual nodes, whereas consistent hashing does. As a result, range-based hashing may not be as effective at distributing keys evenly across the cluster, as it does not allow for a finer-grained control over the distribution of keys.
Overall, consistent hashing is generally considered to be a more efficient and scalable hashing algorithm compared to range-based hashing, especially in situations where the server configuration is likely to change frequently.
Q. When should one use range based hashing?
Range-based hashing is a type of hashing algorithm that assigns keys to servers based on the range of hash values that the key falls within. It is typically used in situations where the server configuration is fixed and does not change frequently, and where the keys are distributed evenly across the servers in the cluster.
One potential use case for range-based hashing is in distributed storage systems, where the keys are the file names and the servers are the storage nodes. In this case, range-based hashing can be used to evenly distribute the files across the storage nodes based on the hash values of the file names.
Another potential use case is in distributed caching systems, where the keys are the cache keys and the servers are the cache nodes. In this case, range-based hashing can be used to evenly distribute the cache keys across the cache nodes based on the hash values of the keys.
Overall, range-based hashing is best suited for situations where the server configuration is fixed and does not change frequently, and where the keys can be evenly distributed across the servers in the cluster. It may not be as efficient or scalable as other hashing algorithms, such as consistent hashing, in situations where the server configuration is likely to change over time.
What about when you need to search for a range of keys will range be better
Range-based hashing is a type of hashing algorithm that assigns keys to servers based on the range of hash values that the key falls within. It is typically used to distribute keys evenly across a cluster of servers, rather than to facilitate the search for a specific range of keys.
If you need to search for a range of keys, it may be more efficient to use a different data structure or indexing scheme that is better suited for range queries. For example, you could use a sorted data structure, such as a balanced tree or a hash table with a secondary index, to store the keys and perform range queries more efficiently.
Alternatively, you could use a distributed database or search engine that is designed to handle range queries across a cluster of servers. These types of systems typically use distributed indexing and partitioning techniques to support efficient range queries across a large dataset.
Overall, while range-based hashing can be useful for evenly distributing keys across a cluster of servers, it may not be the most efficient choice for searching for a specific range of keys. In those cases, it may be better to use a different data structure or system that is specifically designed for range queries.
Q. Why did redis use range based hashing?
A. Redis uses range-based hashing as an implementation detail of its hash data structure, which is used to store key-value pairs. Range-based hashing is a technique that maps a hash function to a range of integers, rather than to a single integer. This allows Redis to store hash keys in a contiguous range of memory, which can improve performance and make it easier to manage the hash data structure.
Range-based hashing works by applying a hash function to a key and then mapping the resulting hash value to a range of integers. For example, if the hash function returns a value between 0 and 99, the range-based hash function could map that value to an integer between 0 and 99, such as the value 37.
Range-based hashing can be more efficient than other forms of hashing because it allows Redis to store the keys in a contiguous range of memory, which can be faster to access than a scattered set of keys. Additionally, range-based hashing can make it easier to manage the hash data structure, since all of the keys are stored in a contiguous range.
Overall, Redis uses range-based hashing as a way to efficiently store and manage key-value pairs in its hash data structure.
Q. What hashing does Cassandra use?
A. Yes, Apache Cassandra does use consistent hashing as part of its distributed data storage and management system.
Consistent hashing is a technique for distributing keys across a large number of nodes in a distributed system in such a way that the distribution of keys is evenly balanced across the nodes, and the addition or removal of nodes has minimal impact on the distribution of keys.
In Cassandra, consistent hashing is used to distribute data across the nodes in a cluster. When a piece of data is inserted into Cassandra, the partition key is hashed using the Murmur3 hash function to produce a token. The token is then used to determine which node the data should be stored on based on the node’s position in the consistent hash ring.
This allows Cassandra to evenly distribute data across the nodes in the cluster, and it also allows the cluster to scale out easily as new nodes are added or removed.
I hope this helps! Let me know if you have any questions.
Q. What other types of hashing is used in sharding data?
A. There are several different techniques that can be used for sharding data in a distributed system. Some of the most common techniques include:
- Range-based hashing: In this approach, data is divided into ranges based on the values of certain key columns, and each range is assigned to a specific node in the cluster.
- Consistent hashing: In this approach, data is distributed across the nodes in a cluster based on the position of the node in a consistent hash ring.
- Rendezvous (or highest random weight) hashing: In this approach, data is distributed across the nodes in a cluster based on the result of a hash function applied to both the key and the node identifier.
- Directory-based hashing: In this approach, a central directory is used to map keys to nodes in the cluster.
There are also various hybrid approaches that combine multiple sharding techniques in order to achieve specific goals, such as improving performance or reducing the impact of node failures.
Q. Why would rendezvous be used over consistent hashing?
A.There are a few reasons why Rendezvous hashing might be preferred over consistent hashing in certain situations:
- Better distribution: Rendezvous hashing is designed to evenly distribute keys across the nodes in a cluster, which can help to improve performance and scalability. In contrast, consistent hashing can sometimes result in uneven distribution of keys, especially when there are a large number of nodes in the cluster.
- Improved load balancing: Rendezvous hashing allows for dynamic load balancing as nodes are added or removed from the cluster, which can help to improve the overall performance and reliability of the system. Consistent hashing can also handle changes in the number of nodes, but it may require the use of virtual nodes, which can add complexity to the implementation.
- Greater flexibility: Rendezvous hashing allows for more flexibility in terms of the number and capacity of nodes in the cluster. It can be used with a variable number of nodes, and the capacity of each node can be changed without affecting the overall distribution of keys.
That being said, consistent hashing has its own set of advantages, and it may be the better choice in certain situations. It is important to carefully consider the requirements and constraints of the distributed system when deciding which sharding technique to use.
Q. Is there any commercial system using rendezvous?
Rendezvous hashing is a technique for distributing keys across a large number of nodes in a distributed system, and it has been used in a number of commercial systems. Some examples of systems that have used Rendezvous hashing include:
- Amazon’s DynamoDB: Amazon’s DynamoDB is a fully managed NoSQL database service that uses Rendezvous hashing to distribute data across a cluster of nodes.
- Microsoft’s Azure Table Storage: Azure Table Storage is a NoSQL key-value store that uses Rendezvous hashing to distribute data across a cluster of nodes.
- Google’s Bigtable: Google’s Bigtable is a distributed column-oriented database that uses Rendezvous hashing to distribute data across a cluster of nodes.
These are just a few examples, and there are likely many other commercial systems that use Rendezvous hashing as well.
Q. How is Rendezvous hashing different from regular hashing?
In regular hashing, the hash function maps each key to a specific node in the cluster. For example, if there are four nodes in the cluster and the hash function is designed to map keys to nodes based on the modulus of the hash value, then key 1 might be mapped to node 1, key 2 might be mapped to node 2, and so on.
In contrast, Rendezvous hashing uses a hash function to calculate a weight for each key-node pair, and it selects the node with the highest weight for each key. This allows for more flexibility in terms of the number and capacity of nodes in the cluster, as the weights can be adjusted to reflect changes in the capacity of the nodes.